


| 本班介紹 | 活動議程 | 專題介紹 | 歷屆成果展 |




















學員將於活動中簡報專題發想動機、技術架構、開發心得、預計成果等,並於簡報後和現場企業來賓進行交流。 歡迎AI人工智慧、機器學習開發、嵌入式系統開發、韌體開發等技術領域相關企業蒞臨交流。
艾鍗辦訓,秉持著「為用而訓」之原則,幫助學員培養符合業界所需的職能。本此成果展的班隊為數據分析暨機器學習應用班。學員們經過3個多月的紮實的實作學習,產出「為用而生」的技術作品,迫不及待向企業夥伴們展現心血成果。本活動免費,歡迎企業廠商到場來交流喔!


|
||||||||||||||||||||||||||||||||||||||||||||||||||
活動時間
113年10月07日 (一) 下午13:30~16:30
活動地點
集思交通部會議中心2樓(台北市中正區杭州南路一段24號)
若您有停車需求,屆時歡迎停至"中華電信仁愛停車場(大樓B3)",本公司人員將再協助您處理停車費用
活動報名
聯絡窗口:張先生 Email住址會使用灌水程式保護機制。你需要啟動Javascript才能觀看它 | (02)2316-7734


近年來,多項調查(包括國家衛生研究院、民間基金會及市調公司)顯示,國人外食比例接近七成,尤以早餐及午餐的比例最高。根據國民健康署健康促進統計年報,2017至2020年18歲以上人口過重及肥胖率已達58.4%,且呈逐年上升趨勢。
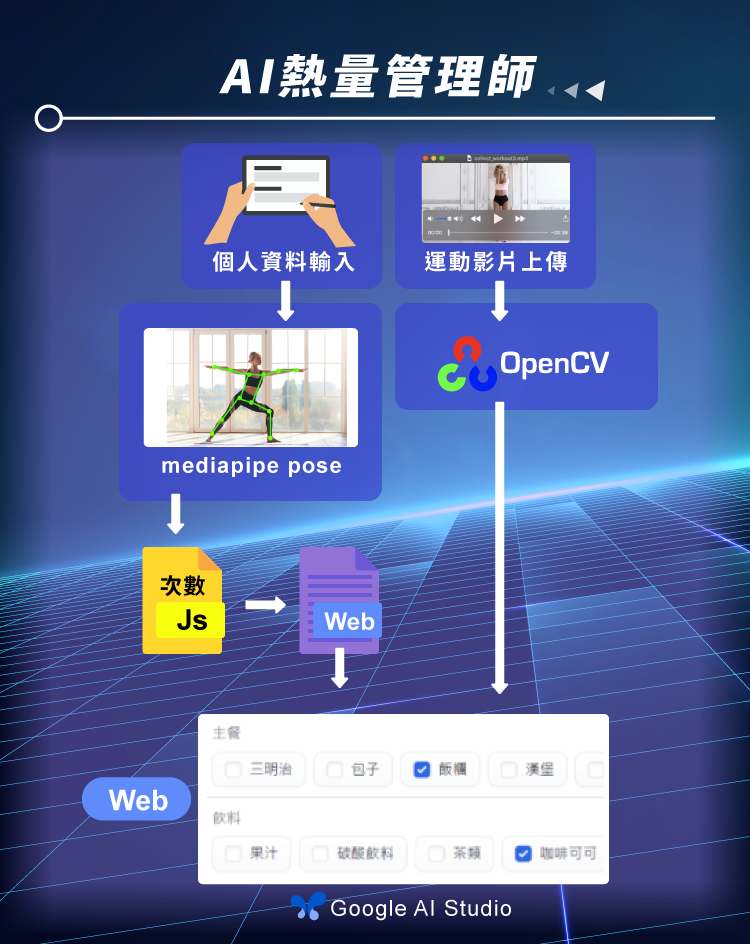
有鑑於此,本專題針對此問題提出解決方案。系統將根據使用者輸入的基本資料,包括性別、身高、體重和年齡,我們可以估算其基礎代謝率(BMR)。再結合運動消耗的熱量,便能計算出使用者每日的總熱量消耗。若每日攝取的熱量低於總消耗熱量,使用者便能有效降低肥胖風險。在運動消耗熱量的估算上,我們先透過 OpenCV 擷取影像,並利用 Google AI Studio API 辨識四種運動類型:伏地挺身、仰臥起坐、引體向上及深蹲。確定運動類型後,通過 Mediapipe 即時追蹤人體骨架和關節位置,根據關節角度的變化來計算運動次數,進而推算出不同運動類型與次數所消耗的熱量。
我們設計了一個網頁使用者介面,包含 BMR 計算、運動影片上傳與食物選擇區。使用者選取食物後,系統會自動累加食物熱量,若超過每日總消耗熱量,系統將發出警示。此外,我們還運用檢索增強生成(RAG)技術,為使用者提供專業的健康建議,協助他們做出更健康的飲食選擇。
AI熱量管理師-專題簡報
AI熱量管理師-專題作品Demo



本專題旨在開發一個電影分類與賣座電影預測系統。我們首先對資料集進行清理與處理,提取的主要特徵包括電影名稱、摘要、導演與演員名字,以及電影進入排行榜的次數等。文字特徵則透過 BERT 模型轉換為深層語義特徵向量。
- 進行電影的多標籤分類,如動作、喜劇、科幻等。
- 透過歷史排行的紀錄特徵,預測新電影在市場上的排行表現潛力機率。
- 針對電影描述生成精準關鍵字推薦,以輔助市場行銷人員撰寫影片文案。
- 系統具備自動文案評分功能,根據文案流暢度與內容相關性給出評分,協助影視行銷人員改進文案的內容。
我們採用 DNN 網絡構建多標籤分類模型,使一部電影能同時被歸類為動作、喜劇、科幻等多種類型。由於資料集中包含每週 TOP10 電影的歷史記錄,DNN 模型還能進行電影進榜次數的回歸估計,進榜次數越高,電影成為賣座片的可能性越大。此外,我們應用了 NLP 自然語言處理技術,從賣座電影中的文案提取關鍵詞與語言特徵,這些詞彙可用於撰寫電影廣告文案,為市場行銷企劃人員提供有力支持,從而提升宣傳效果。

串流平台Netflix熱門電影
與節目特徵分析
及排行上榜預測平台-專題簡報
串流平台Netflix熱門電影
與節目特徵分析及
排行上榜預測平台-專題作品Demo



類流感症狀包括發燒、頭痛、肌肉痠痛、疲倦、流鼻水、喉嚨痛和咳嗽等,嚴重時可能引發併發症,甚至導致死亡。
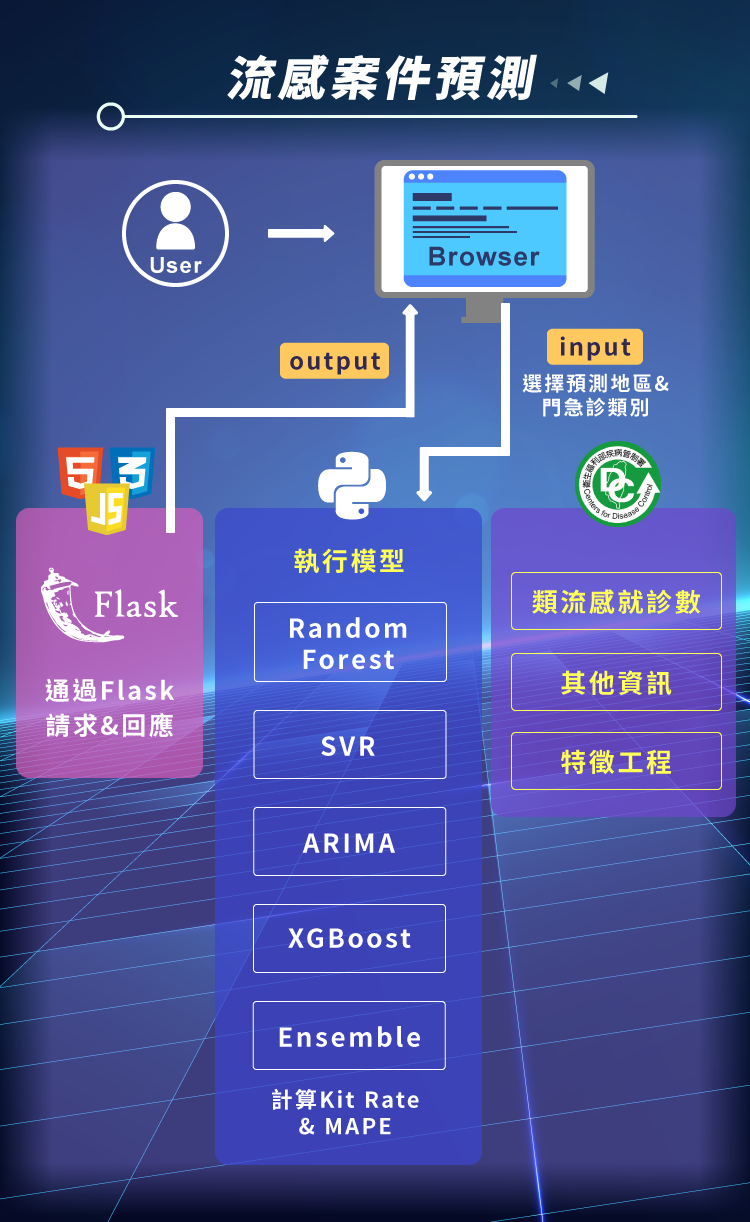
本專題旨在預測台灣及六大地區(台北區、北區、中區、南區、高屏區、東區)未來四週的類流感門診與急診感染人數,藉此提前部署醫療設備與人力資源,同時向民眾提供警示。我們利用政府開放資料進行資料探勘,分析各地染病率、類流感的季節性傳播規律及疫情期間的變化趨勢。基於這些分析結果,我們創建了特徵來建立預測模型,以準確推估未來四週的類流感門診與急診感染人數。模型的預測精度使用兩個指標來評估:Hit Rate和 MAPE。HitRate 用於評估預測的趨勢變動與實際趨勢變動的一致性(值越高,模型對趨勢的預測越準確);MAPE 則衡量實際就診數與預測值之間的誤差比例(值越低,代表模型的預測誤差越小)。我們採用集成學習(Ensemble)進行預測,整合了ARIMA、Random Forest、SVR和XGBoost等多種模型。
最終,我們將這些 AI 模型整合至 Flask Web 框架中,讓使用者透過前端瀏覽器查看疫情趨勢圖及未來四週的感染人數預測。
流感案件預測-專題簡報
流感案件預測-專題作品Demo



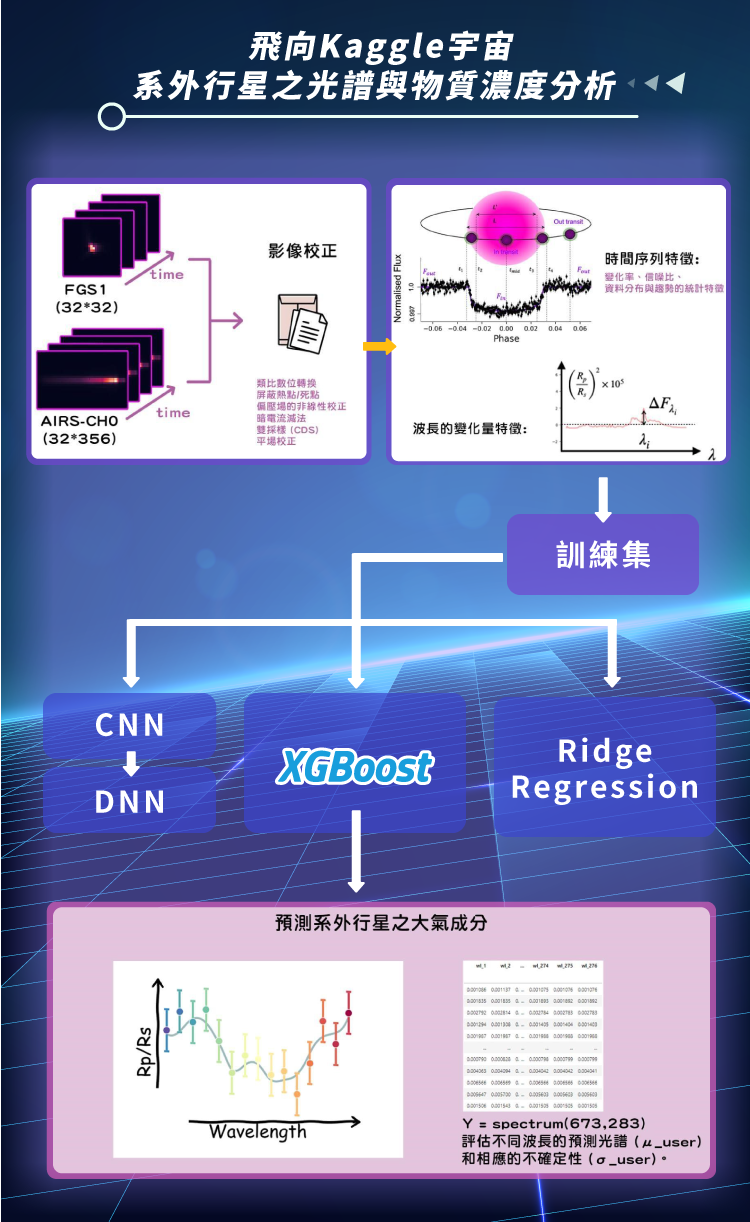
目標是透過太空天文望遠鏡所觀察的 673 顆系外行星的凌日數據,預測其他系外行星大氣的化學光譜與其σ(不確定性範圍)。這有助於進一步理解行星大氣特性,並量化模型預測的精度,為歐洲太空總署於2029年Ariel系外行星探測計畫做準備。
在資料處理上,利用去除噪聲、資料平滑化去觀測凌日現象*(注1)推測該行星其大氣的成分。並使用Lasso Regression、Ridge Regression、XGBoost等方式切入訓練模型。
不僅適用於遙測訊號的處理,還能應用於其他需要涉及大數據、時序資料、影像處理、統計分析和模式識別等領域,例如金融市場趨勢數據分析、電商推薦系統與消費行為分析、社交網路互動數據、醫學影像處理、預測交通流量車輛路徑等。
*注1:當行星凌日時,恆星的光會穿過行星的大氣層,通過分析光譜,可以得知行星大氣的成分和溫度。
飛向Kaggle宇宙-
系外行星之光譜
與物質濃度分析-專題簡報
飛向Kaggle宇宙-
系外行星之光譜
與物質濃度分析-專題作品Demo



在這裡專題的描述中,目的是解決貸款者缺乏傳統信用數據的問題,並通過數據科學的方法來提高貸款預測的準確性,即使是那些沒有足夠信用歷史的人也可以被公平地評估償還能力。
專題描述中提到了三個重要的機器學習模型:XGBoost、LightGBM、CatBoost,這些模型擅長處理大量特徵和複雜的數據,並且已在金融風險預測中取得了不錯的效果。
這專題的挑戰包括:
- 整理異構且複雜的資料,將不同類型的數據統一並轉化為可供模型使用的形式。
- 優化模型的參數,並在多個模型中進行比較,以找到最具預測能力的模型。
- 在Kaggle競賽中挑戰其他參賽者,力爭在排行榜上取得前10%的排名。

Kaggle_貸款風險預測模型開發-專題簡報
Kaggle_貸款風險預測模型開發-專題作品Demo



