


| 本班介紹 | 活動議程 | 專題介紹 | 歷屆成果展 |





















學員將於活動中簡報專題發想動機、技術架構、開發心得、預計成果等,並於簡報後和現場企業來賓進行交流。 歡迎AI人工智慧、機器學習開發、嵌入式系統開發、韌體開發等技術領域相關企業蒞臨交流。
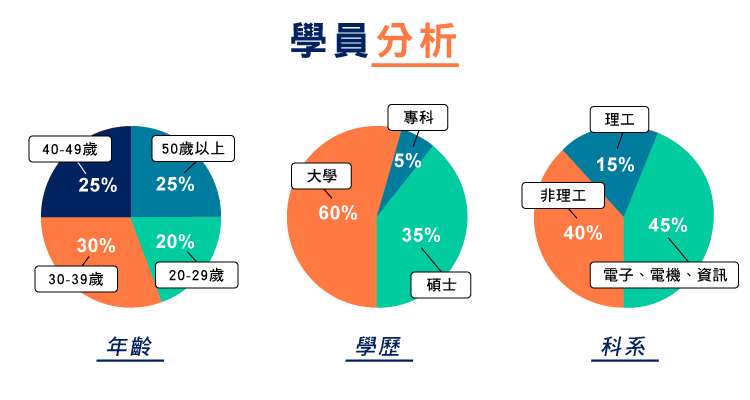
艾鍗辦訓,秉持著「為用而訓」之原則,幫助學員培養符合業界所需的職能。本此成果展的班隊為數據分析暨機器學習應用班。學員們經過3個多月的紮實的實作學習,產出「為用而生」的技術作品,迫不及待向企業夥伴們展現心血成果。本活動免費,歡迎企業廠商到場來交流喔!


|
||||||||||||||||||||||||||||||||||||||||||||||||||


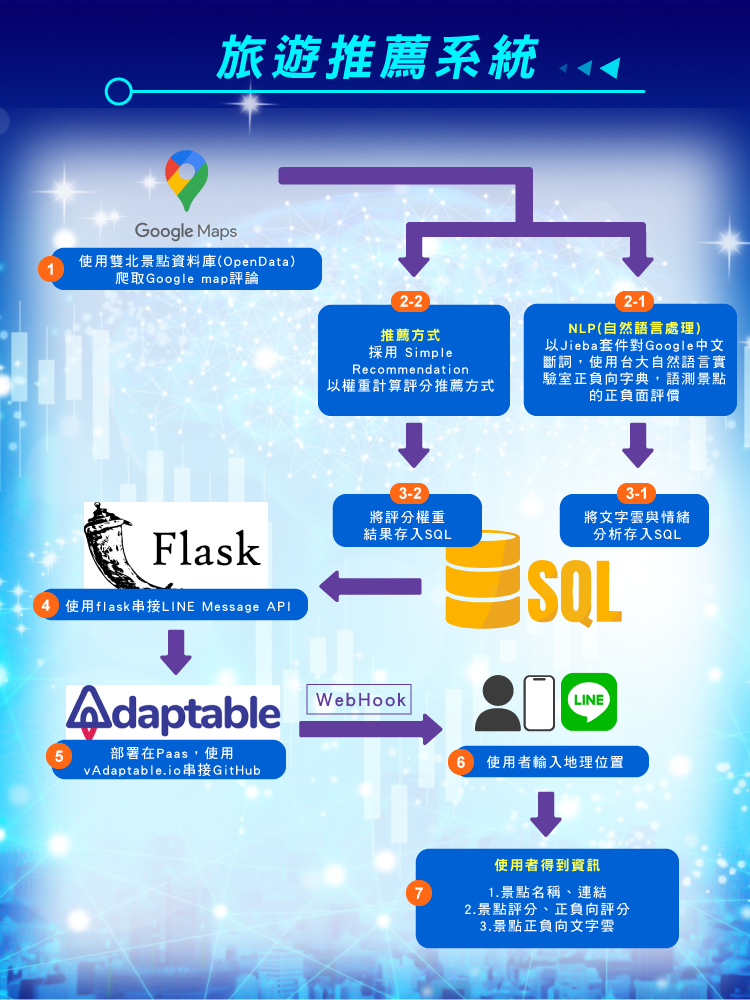
在資訊發達的當代,網路旅遊訊息五花八門,我們常常到了一個景點,卻不清楚下一站能去哪裡。很多人都會從網路上快速看了幾篇文章或依照Google Map的顆星評分來決定下個景點,但經常得到的結果是失望大於預期。因此,我們希望開發一個 ”Tourist Line Spot”系統,它能根據使用者的所在位置,自動幫使用者看完所有的Google map評論並提出一份景點推廌清單。
目前我們以雙北市提供的旅遊景點開放資料(OpenData)作為我們的景點資料庫。依照使用者的地理位置,利用Google Map API找出使用者附近的景點後,提供推廌分數在前5名的景點。景點推廌分數的高低是由Google Map的評論數量 (即熱門程度)、Google Map顆星評比以及景點正負面因子的公式所決定。其中,景點的正負面因子,是用LSTM模型對該景點的Google map留言內容作情緒分析的結果,其值介於0到1。愈接近1表示愈正面愈值得推廌,而接近0表示愈負面愈不值得推廌。 此外,我們也對留言的評論內容,依照頻率最高的關鍵詞建立文字雲,以凸顯該景點的熱門話題。
若”Tourist Line Spot”系統能朝向商業開發,也會加入廣告投放或者或商家合作的商業機制,甚至進一步採付費訂閱制,讓付費會員可以快速得到一手資訊外及額外優惠等功能。
旅遊推薦系統-專題簡報
旅遊推薦系統-專題作品Demo



藥廠開發新藥的傳統作法,是不斷在實驗室以實作的方式,找尋最佳的生產環境。而人工智慧模擬最佳環境參數,協助研究人員減少實作次數,縮短研發時程,已是各藥廠的努力方向。其中,大分子藥物更是推動藥物研發的新動能,而酵素做為大分子生物催化劑,它能加快化學反應的速度(catalysis),有助於減少生產資源,加速生產過程;同時部分酵素也可以做為大分子藥物的原料。
然而,酵素作用的溫度有著十分嚴苛的條件,加熱時或與化學變性劑接觸時,酵素結構會發生“去摺疊(protein denaturation)”,原有的結構被打亂,活性也往往隨之喪失。 因此,如果能開發出具有效率的計算方法,來尋找不同酵素和配合臨界溫度,便能預測酵素的蛋白質的穩定性,即能預測不同酵素的蛋白質序列其去摺疊時的最高溫度(或稱熔點),將會有巨大的科學意義。
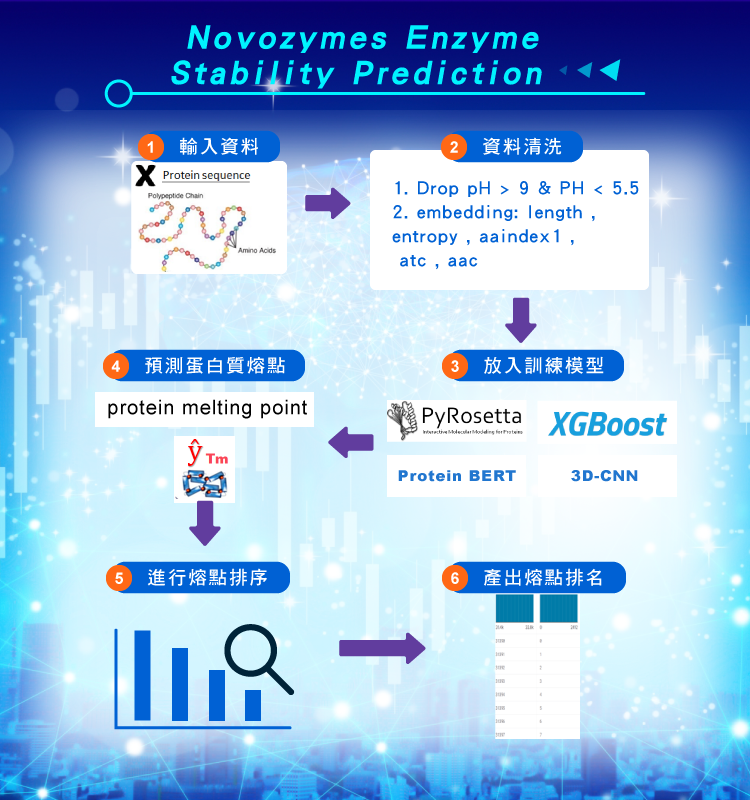
本研究案是以Kaggle 競賽中的Novozymes Enzyme Stability Prediction competition作為立基點,而由官方所提供的train data,包含蛋白質序列資料(proteins sequence) 、PH值和對應的熔點(tm),而本次的目標在於預測test data的熔點值的排名。
首先我們先對於Kaggle所提供的train data進行觀察,並發現不合理資料後,進行資料清理。完成後我們額外增加來自AlphaFold2、Rosetta等生物資料庫數據。由於擴增訓練集資料欄位不同,所以我們建立不同的酵素序列的特徵向量。也因為酵素有四級結構(胺基酸序列到立體結構),我們以從不同的角度切入酵素穩定性的問題,所以我們嘗試以不同種類的模型解析酵素的穩定性。
接著建立3種不同的迴歸模型,包含XGBoost及Protein BERT和CNN。最後將上述模型整合,建立Ensemble模型,進而得到最終的預測結果,並利用Spearman相關係數,進行Ensemble模型的效能的比較。
預測酶得熱穩定性-專題簡報
預測酶的熱穩定性-專題作品Demo



近3年疫情延燒,為降低排隊群聚傳染風險,少子化以及超商、超市、零售商招募員工日益困難,使得2016年的Amazon Go的新零售概念的無人商店-店內沒有服務人員及收銀人員,顧客進入後,自助購物、自助結帳,不用排隊付款,讓顧客「拿了就走」的新型消費模式,再度受到關注。台灣目前7-11及全家都設立少數的無人商店,但尚不普及。
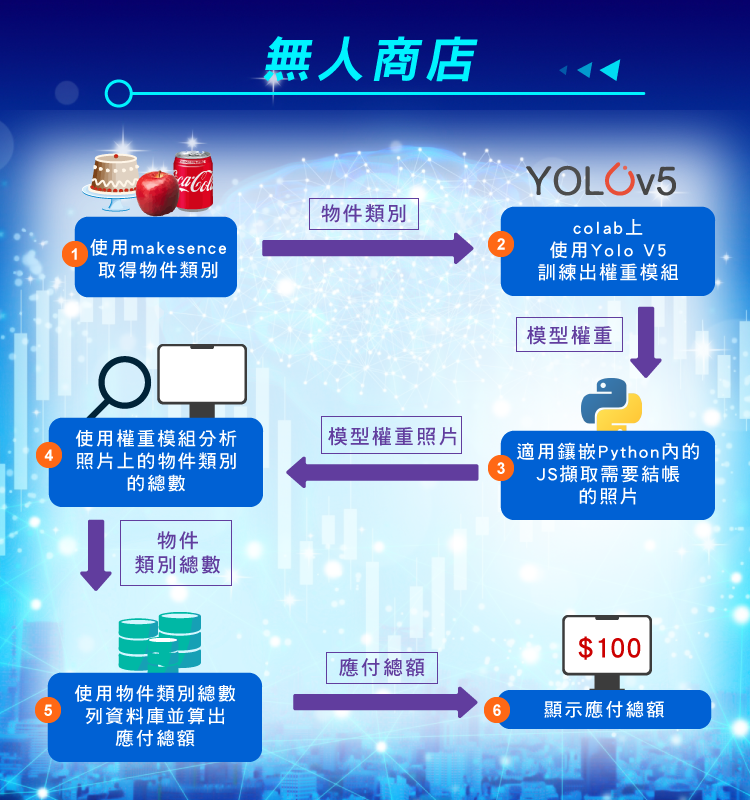
本組希望完成一個自動結帳系統,透過AI快速辨識技術,直接結帳。主要解決少子化勞動力日減、零售業員工離職率高、訓練成本高的問題、排隊人龍導致結帳速度緩慢,以及一般麵包店、水果店沒條碼結帳錯誤率高等等問題。
本組應用此次課程所學的3個主要科目:深度學習、資料庫SQL及專案管理,選擇高辨識力的YOLOv5(CNN)作為深度學習的框架、普遍的附有web camera的 pc為硬體平台,顧客只需將商品依序用web camera偵測商品,直接在雲端Google Colab用 YOLOv5(CNN)模型,進行物件偵測,傳輸到到本組所設計的MySQL,顯示顧客所購買的商品及金額,再結帳。
本組希望這個簡單又經濟實用的小設計,能佳惠一般麵包店、水果店等小店面,讓無人商店的概念更加普及,不再只是連鎖商店使用。
無人商店-專題簡報
無人商店-專題作品Demo



